
Les Bell
Blog entry by Les Bell
Welcome to today's daily briefing on security news relevant to our CISSP (and other) courses. Links within stories may lead to further details in the course notes of some of our courses, and will only be accessible if you are enrolled in the corresponding course - this is a shallow ploy to encourage ongoing study. However, each item ends with a link to the original source.
News Stories
Autonomous Cyber Defence
As cyber attacks become more prevalent and the consequences of a breach get greater and greater (think of attacks on healthcare, industrial control systems and the Internet of Things), we face increasing manpower shortages. It takes a range of skills across networking, software development, system administration and operations to deal with possible attacks on complex systems, and there simply aren't enough skilled people to go around.
Last week I stumbled across an academic paper which points to the likely future: automated defence using machine learning. The authors are researchers at the US Department of Energy's Pacific
Northwest National Laboratory, which is particularly interested in
techniques to defend industrial controls systems - such as, in
particular, the power grid - against cyber attacks. Their paper first caught my attention because it uses similar techniques to my own research in computational trust, but here they are adapted to cyber defence.
A number of factors have combined to make this automated approach almost practical. Among these is the emergence of an ontology for describing cyber attacks, along with developments in deep learning and, of course, the availability of increasing compute power to solve the problems.
Let's start with the first of these. Attendees at my CISSP courses and university lectures will be familiar with the concept of the cyber intrusion kill chain, first introduced by Lockheed-Martin over a decade ago. This laid out a seven-stage model of a typical sophisticated attack, as attempted by an advanced persistent threat. This influenced the development of MITRE's ATT&CK matrix, which is rather more granular and much more detailed.
This also saw more formalization in the use of terms like Tactics, Techniques and Procedures - tactics are derived from the kill chain's stages and describe high-level activities such as reconnaisance, persistence, C2, collection and exfiltration, while techniques are how the attacker achieves his goal for each tactical stage. In essence, tactics are classes of exploits, like privilege escalation, screen capture or phishing (ATT&CK breaks these down further, with hundreds of sub-techniques). The final level, procedures, equate to the specific exploits which take advantage of vulnerabilities - and these, of course, are now captured in the CVE and CWE databases.
In this model, the attacker works their way along the kill chain, tactic by tactic, using techniques to enable a move to the next stage. In terms of game theory, this is referred to as a stochastic game (or Markov game), in which the entire game is represented by a directed graph, with the probability of transitioning from one state to another state dependent upon the skills and resources of the attacker, versus the skills and resources of the defender. Now take a look at this figure, taken from the paper:
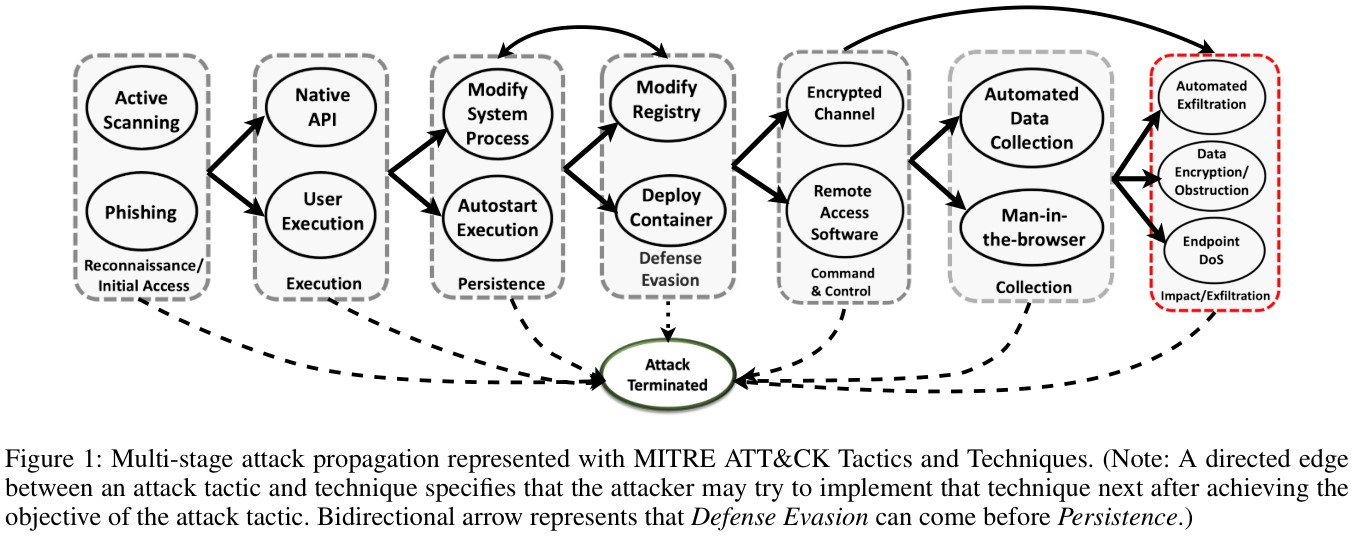
Here, rectangular boxes are tactical stages of an attack, while the ovals within them are techniques that could - if successful - complete that stage and allow the attacker to move on to the next stage.
In their paper, the authors model the behaviour of an automated defender as it tries to block the various stages of the attack. At each stage, the defender does not know which technique the attacker will use next - first of all, the defender may not know all the possible techniques and besides, attackers vary their techniques. Even if it can guess the technique, the specific procedure will be difficult to predict (because of 0day exploits, etc.). In addition, not everything the attacker does may be captured or, if it is, its significance is not known until later.
The game starts in an Attack Initiated state, and the attacker's goal is to get through the stages to the Impact/Exfiltration state (in red above). The defender's goal is to get the game to the Attack Terminated state, which will occur if the attacker runs out of techniques to get to the next stage.
After each attacker action (i.e. procedure - attempted exploit), the defender can choose one of three actions. It can either do nothing, it can react by removing all processes that were used by the attacker in his last attack action, or it can act proactively to block a specific set of API calls or operations in order to prevent the next attack action. However, killing processes and blocking API's is bad for business, and therefore incurs some cost, which the defender will attempt to avoid.
The goal of the automated defender is to develop a policy which recommends the optimal action at each state of the game. It does this using a technique called reinforcement learning, in which it earns a reward (computed by a reward function) for each state - the reward is simply a number which is proportional to how desirable that state is. The defender's goal is to maximise its total rewards in the long run, and it will try to develop a policy in order to do that.
The question is, how to develop that policy? In my own research, I used Bayesian networks to 'learn' the policy, but things have moved on since then, particularly with the emergence of deep learning techniques. In this paper, the authors explored four different Deep Reinforcement Learning approaches - a Deep Q-Network approach (DQN) and three different Actor-Critic approaches.
To run their simulations, they used a fairly grunty Alienware machine (16-core i7 processor, 64 GB RAM, three NVidia GM200 graphics cards) - but that's actually not that big; the machine I am typing this on is similar, only based on an i9. Their software is written in Python (of course) and running in a customized OpenAI Gym simulation environment (I ran my simulations in Java and C, for performance - less necessary today). Compared to the cost of standing up and manning a SOC, this setup is a bargain.
I'm not going to do a deep dive into the learning parameters or the algorithms involved - here, I'm just interested in the security aspects. But the results are encouraging. Overall, the Deep Q-Network approach did best against a range of simulated attacks as soon as possible, although it fell behind when defending against a more skilled and persistent adversary (Av3), who is more likely to quickly identify the right action and not give up.
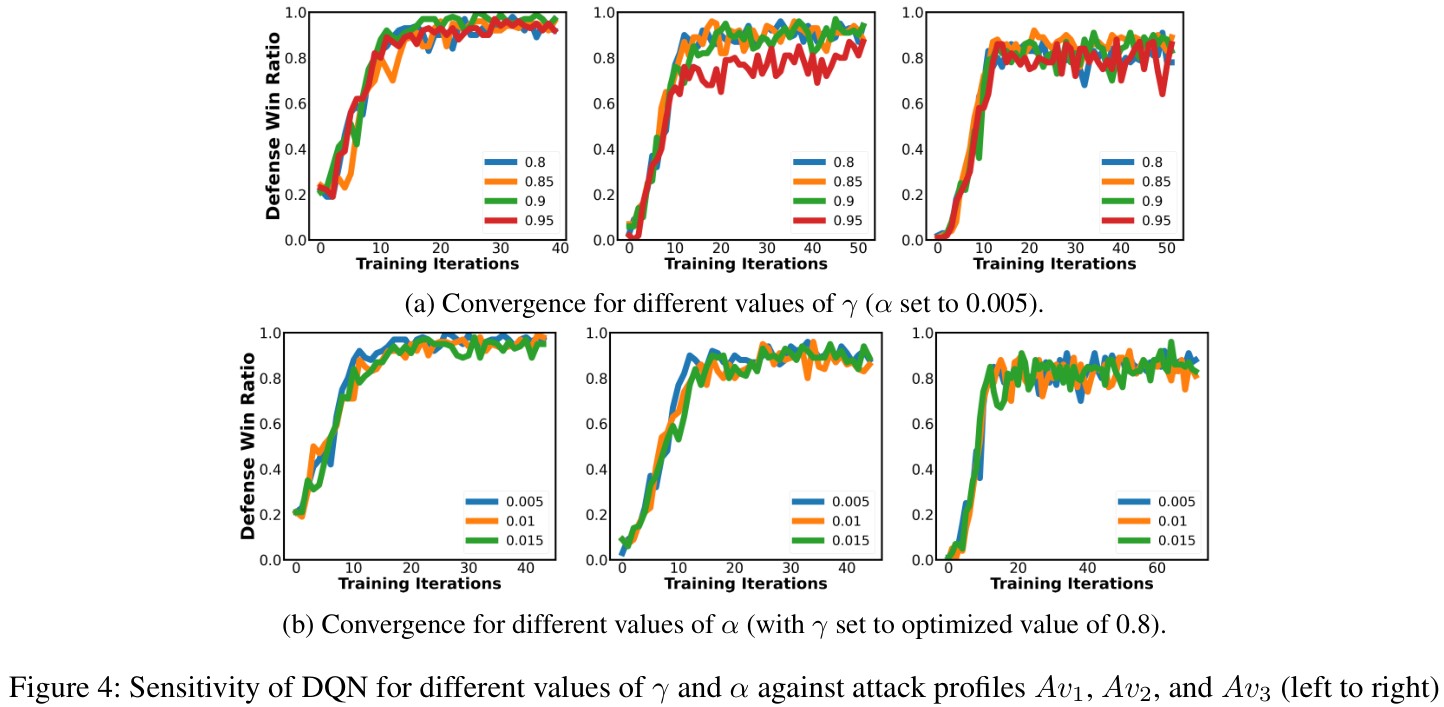
Now, bear in mind this is a simulation based on a relatively small number of tactics and techniques, and modeling the probability of each technique succeeding or failing probabilistically, based on the assumed skill and persistence of the attacker. There were no actual attacks involved, no mining of events from a SIEM, etc - extracting that information from IDS/IPS and SIEM systems is a completely different problem, which others, in both the public and private sectors, are also working on.
But I feel that this type of approach, in which sensors feed event information to a machine learning system which has learned from previous attacks, is likely the way of the future.And bear in mind, this is just one paper, from one group of researchers - there's a lot more going on - but I felt it was worth reporting on, in particular to explain how it relates to other things discussed in our courses.
These developments will take SOAR (Security Orchestration, Automation and Response) to a whole new level. Watch this space.
Dutta, A., Chatterjee, S., Bhattacharya, A., and Halappanavar, M., Deep Reinforcement Learning for Cyber System Defense under Dynamic Adversarial Uncertainties, arXiv, 3 February 2023. Available online at https://arxiv.org/abs/2302.01595.
These news brief blog articles are collected at https://www.lesbell.com.au/blog/index.php?courseid=1. If you would prefer an RSS feed for your reader, the feed can be found at https://www.lesbell.com.au/rss/file.php/1/dd977d83ae51998b0b79799c822ac0a1/blog/user/3/rss.xml.
![]()
 Copyright to linked articles is held by their individual authors or publishers. Our commentary is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License and is labeled TLP:CLEAR.
Copyright to linked articles is held by their individual authors or publishers. Our commentary is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License and is labeled TLP:CLEAR.